Every time you use an app, visit a website, click on a link, fill out a survey or even just scroll on your device, your data is being:
Collected - What you click, search, watch, like or buy
Analyzed - Used to predict your behaviour, interests or identity
Shared or Sold - Passed to advertisers, data brokers or other companies
Why Does This Matter?
You may be targeted with ads, content and potentially misinformation
You could be judged or profiled based on your data (even if it’s not accurate)
You rarely know who has your data (or what they’re doing with it)
So what does this mean for us? Let’s explore how data can be used, what makes certain information sensitive and why it matters.
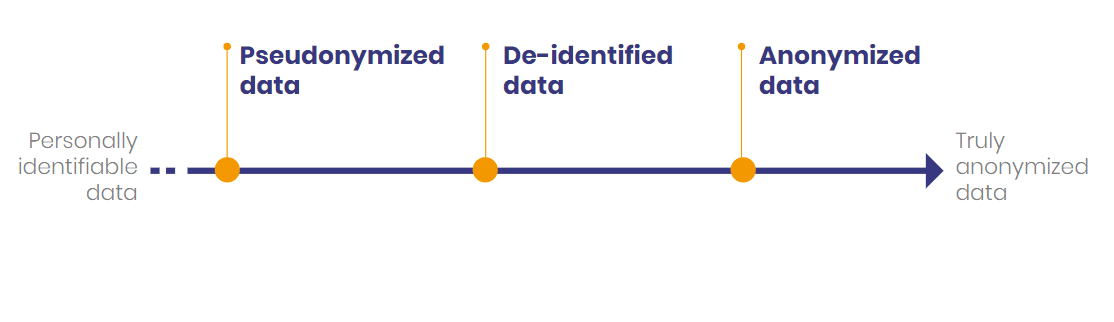
Personally Identifiable Information (PII)
PII refers to any data that can be used to identify a specific individual.
Direct identifiers: These clearly and uniquely point to a person.
Examples: name, social security number, patient ID
Indirect identifiers: These don’t identify someone on their own, but could when combined.
Examples: age, DOB, postal code, race, sex
Personal Data
Data can be identifiable when:
They contain directly identifying information.
It’s possible to single out an individual
It’s possible to infer information about an individual based on information in your dataset
It’s possible to link records relating to an individual.
De-identification is still reversible.
Scenario: Can This Data Identify You?
A fitness app shares anonymized data with researchers. The dataset includes:
Step count per day
General location (postal code)
Age
Time of day the user exercises
Health conditions
Separately, a publicly available dataset includes information from a local running club: names, age groups and 5K race times.
The Mosaic Effect
The “Mosaic Effect” can happens when separate pieces of data, which alone don’t identify anyone, are combined from different sources to reveal personal information or identify an individual.
In 2000, 87% of the United States population was found to be identifiable using a combination of their ZIP code, gender and date of birth.
Convert date of birth to age, or group into ranges
Replace address with town or region
Recategorise rare labels into “other” or “missing”
Abstract people or places in qualitative data (e.g., “Bob” to “[colleague]”)
Generalization Example
Here we will show an example of generalization on the age column:
df_generalized <- df |>mutate(age_group =case_when( age <30~"under 30",TRUE~"30+" ))|>select(-age)df_generalized
# A tibble: 4 × 3
name height_cm age_group
<chr> <dbl> <chr>
1 Joel Miller 182 30+
2 Ellie Williams 160 under 30
3 Tommy Miller 185 30+
4 Abby Anderson 173 under 30
Replacement
Swap identifying info with less informative alternatives
Examples:
Use pseudonyms for names (with securely stored keyfile)
Replace with placeholders (e.g., “[redacted]”)
Rounding numeric values
Creating Pseudonyms
Pseudonyms should reveal nothing about the subject
Good pseudonyms:
Are random or meaningless strings/numbers
Are securely managed (e.g., encrypted keyfile)
Can be generated using tools in Excel, R, Python, SPSS
digest hashed the entire name column as a single object (it’s not vectorized), so mutate recycled the same hash to every row (which is not what we want).
Top- and Bottom-Coding
Limits extreme values in quantitative data
Recode all values above or below a threshold
Example: all incomes above $150,000 become $150,000
Preserves much of the dataset, but distorts distribution tails
Top-coding example
Consider 6ft (182.88cm) is considered our maximum height threshold.
# A tibble: 4 × 3
name age height_cm_noisy
<chr> <dbl> <dbl>
1 Joel Miller 52 182.
2 Ellie Williams 19 160.
3 Tommy Miller 48 186.
4 Abby Anderson 28 174.
Permutation
Swap values between individuals
Makes linking variables across a record more difficult
Maintains distributions, but breaks correlations
Can limit the types of analyses possible
Permutation of Height Values
Here, the height_cm values are shuffled between individuals, preserving the overall distribution but breaking the link between person and value.
# A tibble: 4 × 3
name age height_cm_permuted
<chr> <dbl> <dbl>
1 Joel Miller 52 160
2 Ellie Williams 19 173
3 Tommy Miller 48 182
4 Abby Anderson 28 185