Justify and apply strategies for managing the missing data.
Write a computer script to impute missing values when appropriate
Write a computer script to evaluate the impact that missing data can have on subsequent analyses through simulation.
Reflect on the consequences with regards to the conclusions of the chosen method.
Recognize the importance of utilizing domain knowledge when handling missing data.
Review
Before the midterm we
introduced the problem of missing data
learned different ways to diagnose missingness
defined different missing data mechanisms
used R functions from naniar package, integrated with tidyverse workflow, to analyzed data
introduced some imputation methods
Some more details about imputation
Imputation is not always the solution to missing data
Imputation can reinforce existing biases.
For example, imputing variables like, age, race, gender may introduce biases to the analysis, particularly if missingness is related to social factors.
In other cases, imputation may mask trends in the data over time.
The percentage of missing data matters: less than 5% is generally considered safe to impute; 5%–20% is often acceptable but requires careful diagnostics; 20%–40% calls for caution; and more than 40% are typically unreliable.
When missing data cannot be recovered, it is important to understand why the data are missing and to analyze them accordingly.
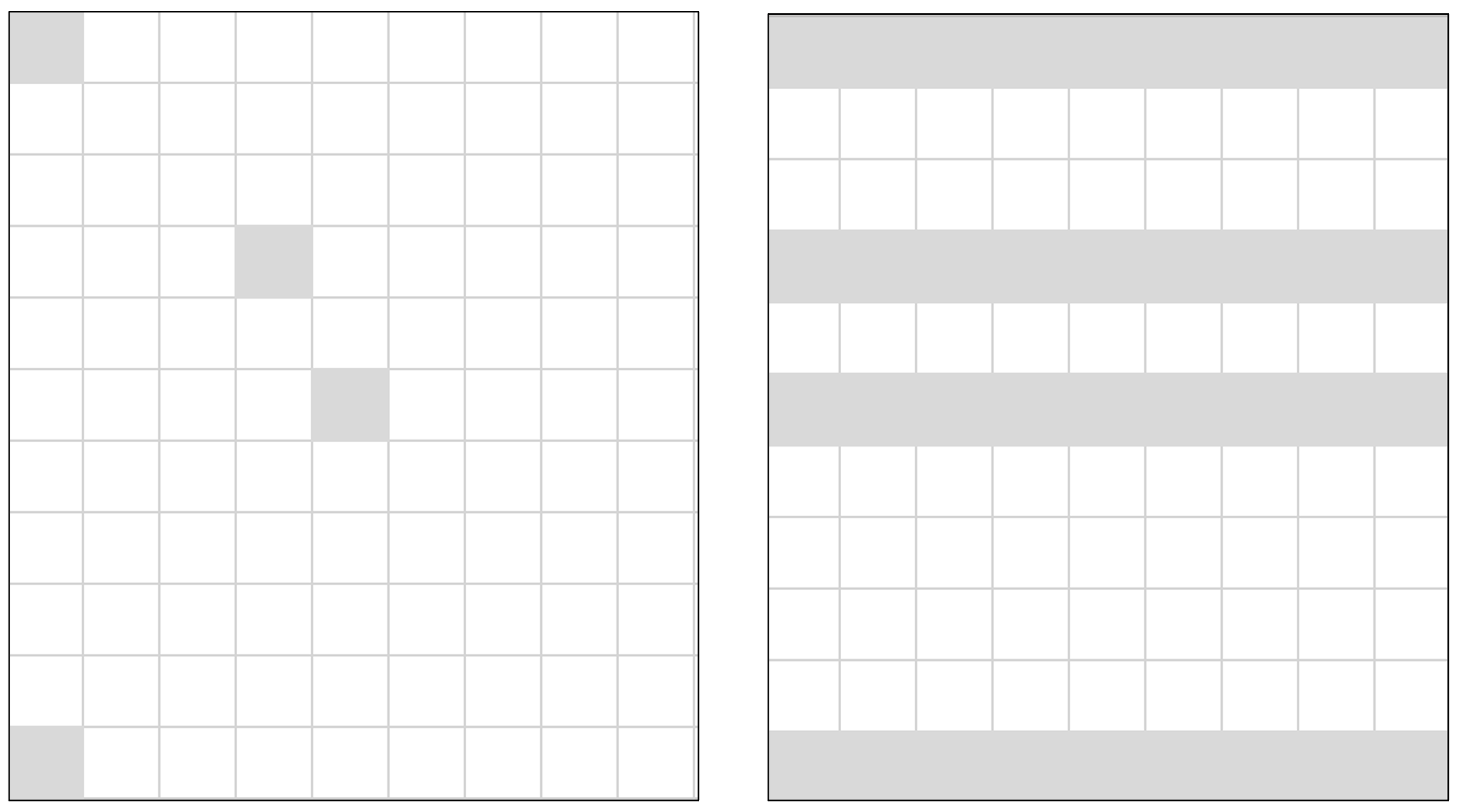
Types of imputation
Listwise Deletion
Retain only complete observations
Simple and widely used
Unbiased under MCAR
Biased under MAR in many cases
Inefficient (larger standard errors due to smaller sample size)
Discards potentially useful data
Deterministic Methods - I
Imputation using a fix value (e.g., the mean, median, or mode of each variable)
Assumes that missing data is either Missing Completely at Random (MCAR) or Missing at Random (MAR).
Reflects the uncertainty inherent in the missing data by introducing many randomly imputed values.
Gives unbiased parameter estimates
Retain the statistical relationships present in the data
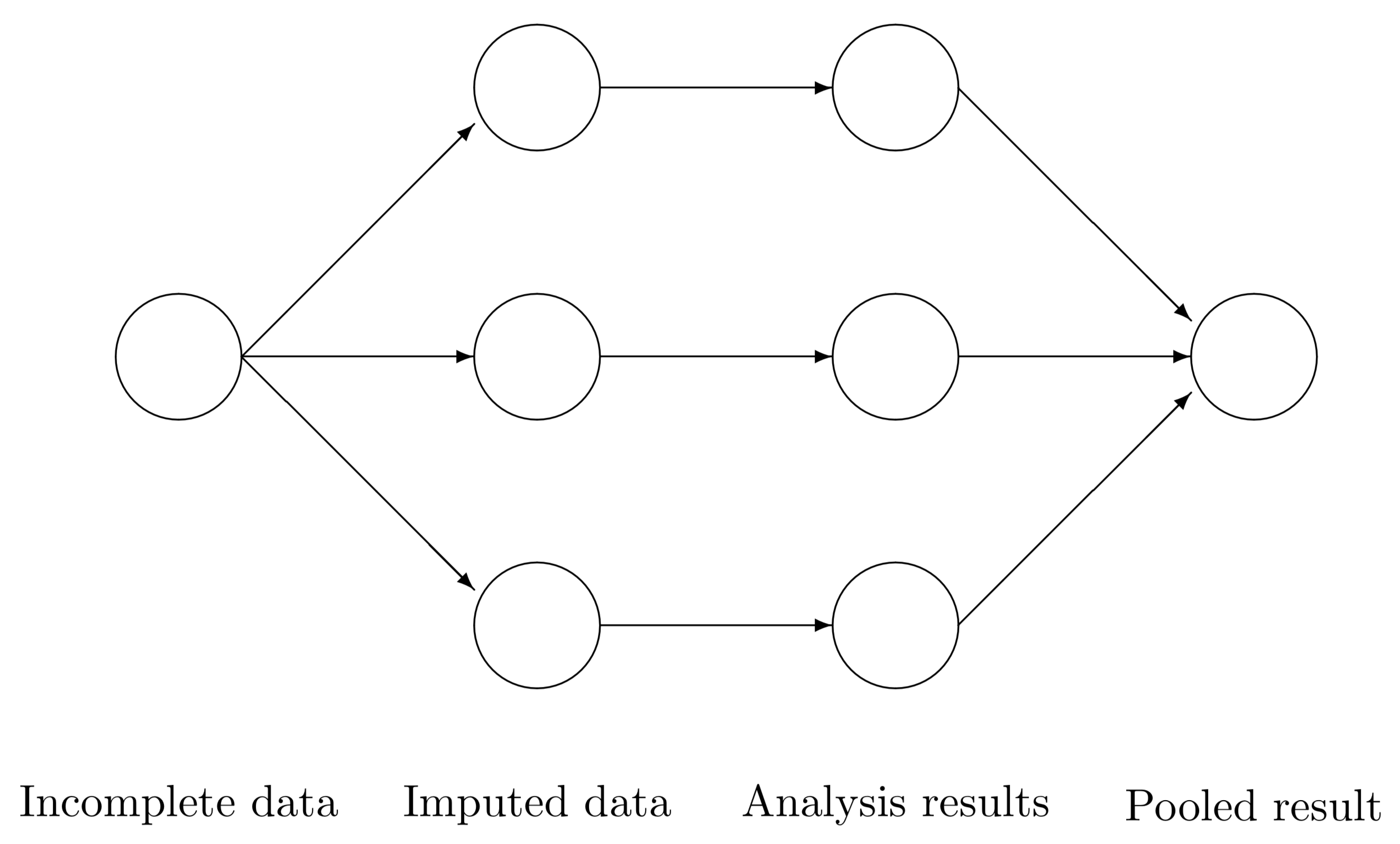
MICE: Multivariate Imputation via Chained Equations
Initialization: Replace missing values with simple initial guesses (e.g., mean or median of observed values).
Imputation: For each variable with missing values, impute it using the other variables as predictors, based on a specified method (e.g., PMM, regression, tree-based methods), including random variation.
Iteration (maxit): Cycle through all variables multiple times to update the imputations.
Multiple Imputations: Repeat to create m complete datasets.