[1] NAA quick visualization

We can see the amount of missingness for each variable, but this summary does not show whether missing values occur together in the same observations.
Joint missigness


Missing Mechanism?

The plot suggests that data is not missing completely at random! but …
MAR vs MNAR

Because x1 and x2 are correlated, the missingness can appear to be related to x1. However, the missingness mechanism depends on the value of x2 itself, which makes it MNAR.
Caution
Visualizations can help rule out MCAR, but they cannot reliably distinguish MAR from MNAR.
When variables are correlated, an MNAR mechanism may look like MAR in plots.
- Deterministic Methods: Mean, Median, Mode Imputation
- Replaces missing values with the mean, median, or mode of the observed data
- Simple and fast to apply
- Reduces variance
- Introduces bias in relationships among variables
- Ignores imputation uncertainty

- Deterministic Methods: Statistical Prediction Models
- Replaces missing values with predictions from an estimated model (e.g., linear regression) using observed values of other variables.
- Preserves relationships between variables
- Assumes relationships that may not be valid
- Ignores imputation uncertainty.

Multiple imputation (MI)
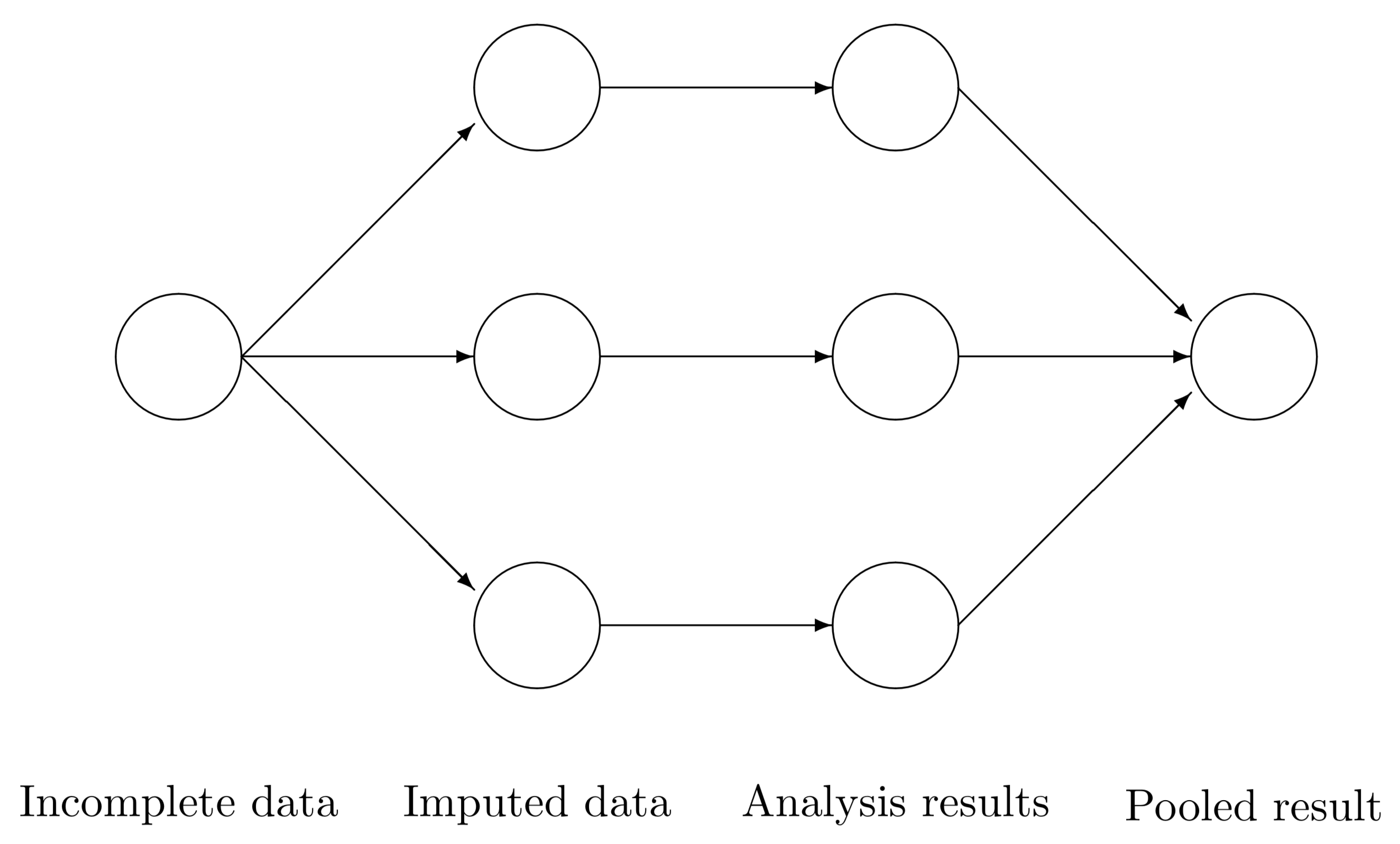
Figure from *Flexible Imputation of Missing Data
Visualizing imputation

Many imputation methods exist but it is important to understand the risk of imputing!
Transparent reporting of imputation decisions is essential for reproducibility and ethical integrity.
Check additional functions in the Missing Book
