


set.seed(200)
sim_stats <- replicate(10000, {
x <- rnorm(100)
c(mean = mean(x),
median = median(x))
})
sim_stats <- t(sim_stats) |> as.data.frame()
sd(sim_stats$mean)[1] 0.1006556[1] 0.1[1] 0.1255247[1] 0.1253314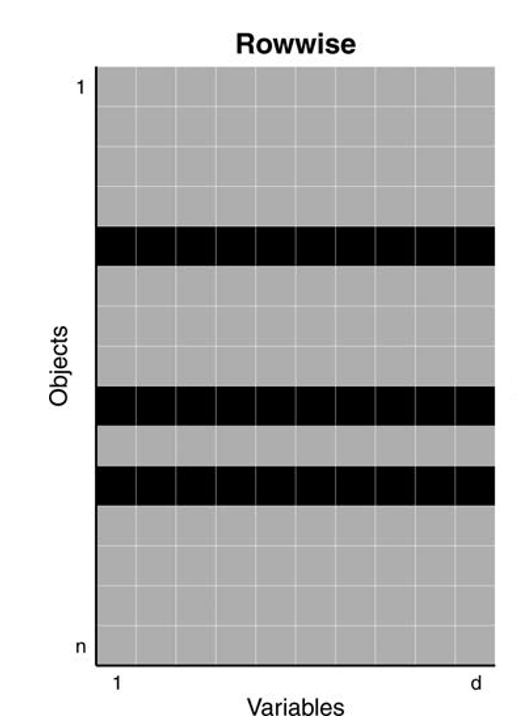
In the 1960s Tukey and Huber introduced the casewise (aka rowwise) contamination model
Treats entire rows as contaminated and coming from a different distribution, even if only values of some variables are unusual
Assumes that less than 50% of the cases (objects) are contaminated
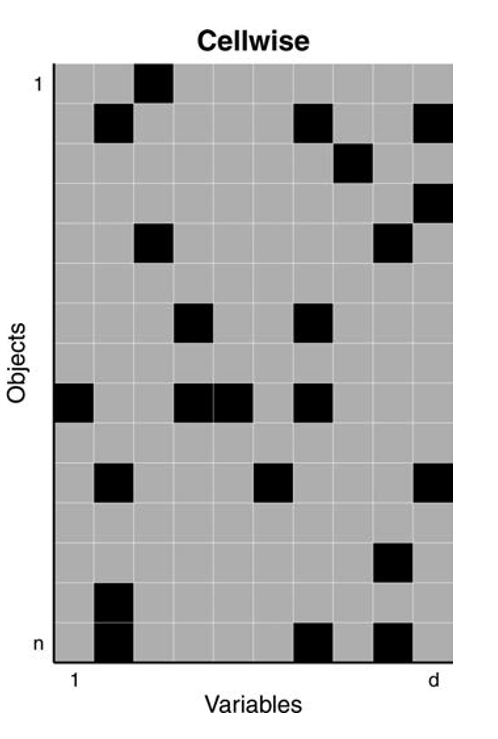
In 2009, Alqallaf, Van Aelst, Yohai and Zamar introduced the cellwise contamination model
Only individual cells are contaminated, with values coming from a different distribution
Any case (row) may contain some contaminated cells
More realistic for high-dimensional data
Data: n = 180 archeological glass spectra with d = 750 wavelengths (Detecting Deviating Data Cells, Rousseeuw & Van Den Bossche, Technometrics 2018)
Before analyzing multivariate datasets, we first need to learn how to identify and handle outlying values in a single variable.
Let’s look at the values of the wavelength V169 in this data
