
Review
An outlier is an observation that deviates from the bulk of the data, an atypical observation.
We defined both casewise and cellwise outliers but focused on univarite outliers.
 We defined and examined by simulations three univariate estimators of location: the mean, the median, the M-estimators.
We defined and examined by simulations three univariate estimators of location: the mean, the median, the M-estimators.
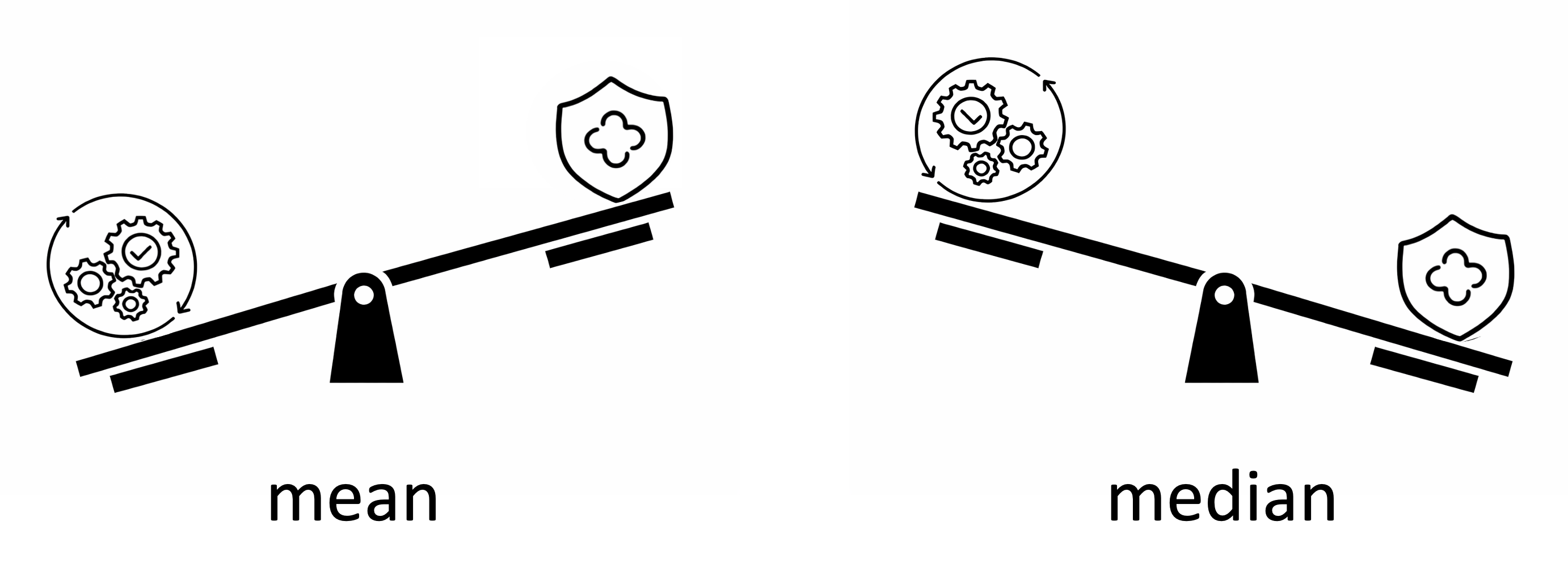
- We learned about the trade-off between robustness and efficiency.
Definition: Efficiency
Efficiency measures how precise an estimator is, the more efficient the estimator, the less it varies across samples.
Relative efficiency compares two unbiased estimators by the ratio of their variances.
Since the sample mean is an optimal estimator (MLE) under the Normal distribution, we measured the efficiency of robust estimators in comparison to the sample mean, for example:
\[\frac{\text{Var}(\text{sample median})}{\text{Var}(\text{sample mean})}\]
From one variable to an entire dataset
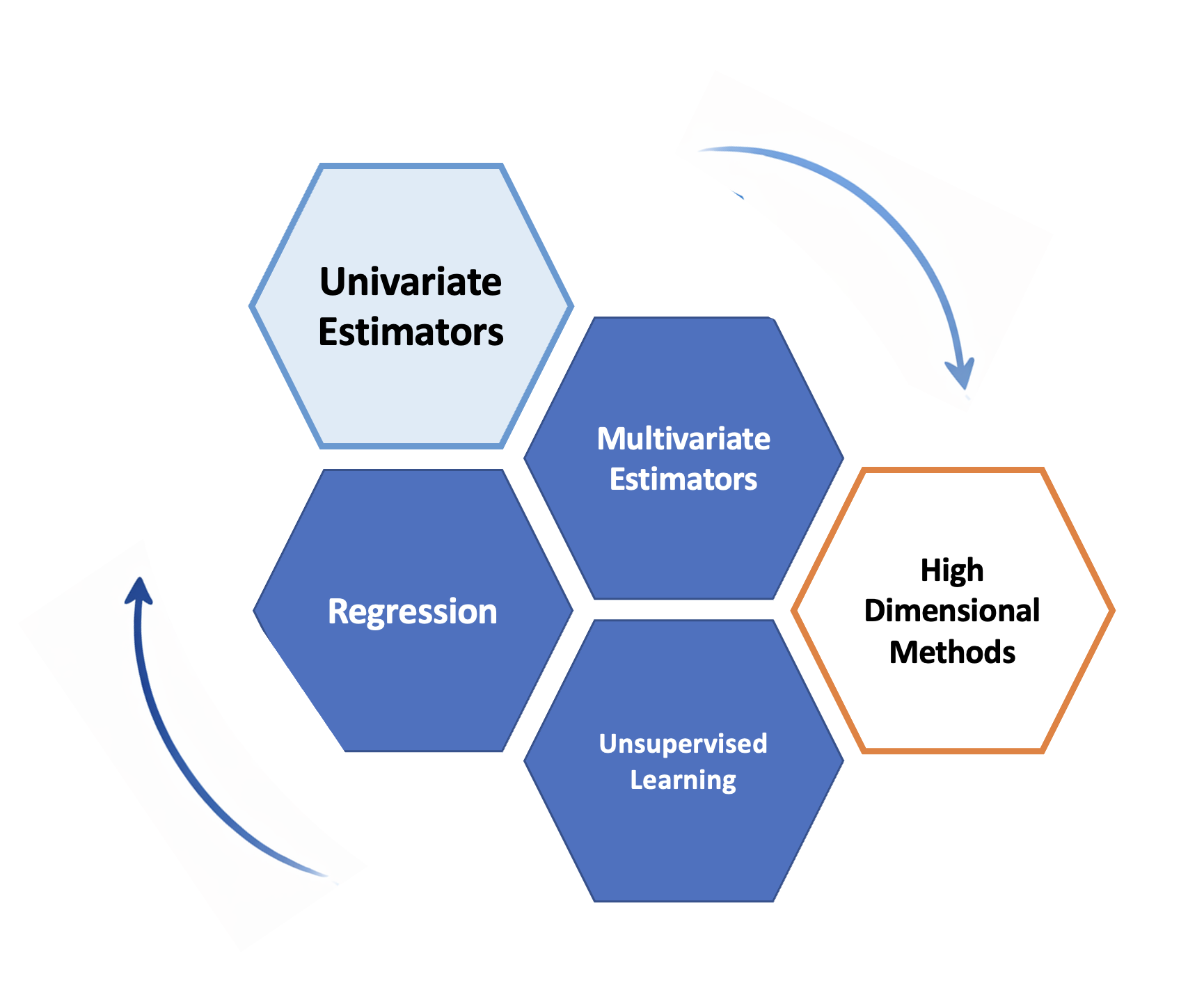
Three core tasks:
Estimating multivariate paramters (e.g, location and covariance)
Modeling relationships (e.g., regression)
Discovering structure (e.g., unsupervised learning)
Goal for today
- What is a multivariate parameter?
- How do we estimate multivariate location and scatter robustly?
- How do we detect multivariate outliers?
- Why do cellwise outliers need different tools?
Correlation matrix
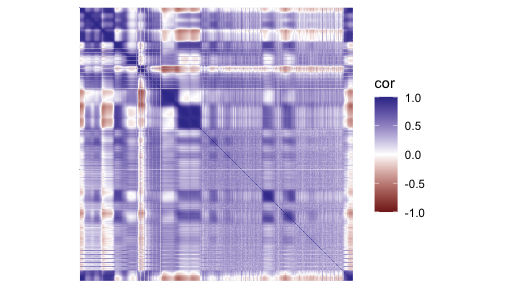
- Each entry measures pairwise linear association between variables
- Diagonal entries are 1
Multivariate estimators in R
Let’s start by visualizing pair-wise estimates for 4 variables

- Distribution of each variable in the diagonal
- Pairwise scatter plots and correlations off-diagonal
- Pairwise sample means shown as red crosses

Outliers are visible in the (marginal) distribution of V169, so it is not surprising that they affect pairwise summaries too.
Multivariate outliers

Some observations deviate from the overall trend, while others reinforce it.

Points (rows) with a squared MD exceeding the cutoff are flagged as rowwise outliers
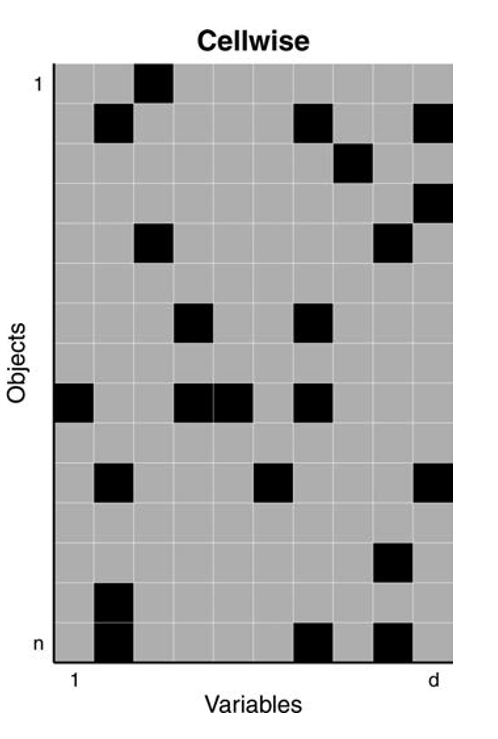
But what if only a few cells are contaminated in many rows?
- every row may contain at least one bad entry
- rowwise methods can lose too much information
- we need methods that work more coordinatewise
This motivates wrapping and DDC.
Robust correlation by wrapping
In the spirit of Huber’s estimation, wrapping have been proposed to compute robust correlations (fast):
- robustly standardize each variable
- transform extreme values with a bounded function
- compute ordinary correlations on the transformed data
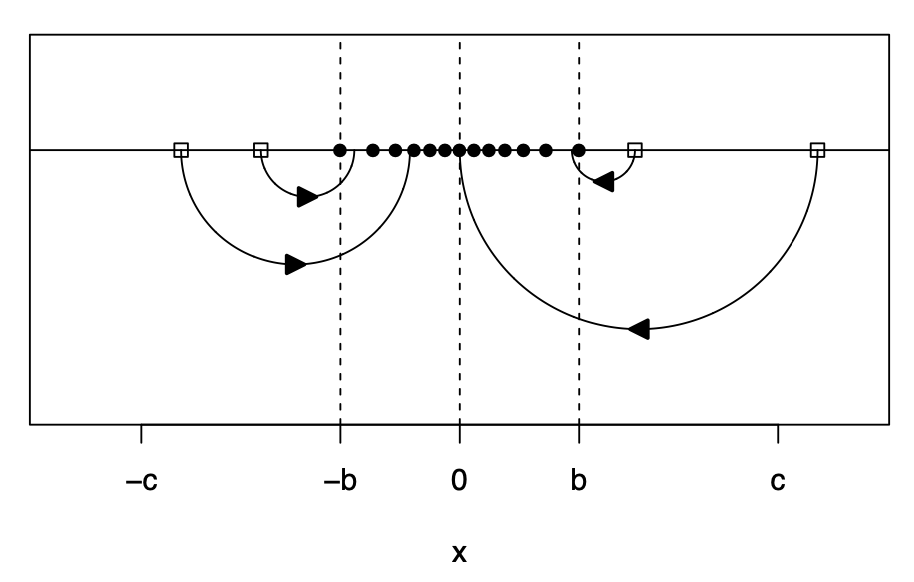
So we keep the speed and matrix structure of classical correlation, but gain robustness.
from Raymaekers, J., and Rousseeuw, P.J, (Technometrics 2021)
